Beam Search Algorithm
Objetivos
• Para mostrar cómo el haz de búsqueda algoritmo utiliza una función heurística y un ancho de haz dado en un intento de simular la búsqueda primero en amplitud de una manera eficiente en la memoria.
• Para enfatizar la importancia de limitar el consumo de un gráfico en la búsqueda de la memoria cuando la búsqueda de soluciones a los espacios de gran problema.
• Para demostrar las fortalezas y debilidades del algoritmo de la viga de la búsqueda.
Preparación
Para entender este algoritmo, debe estar familiarizado con el concepto de un gráfico como un grupo de nodos o vértices y aristas que conectan estos nodos. También es útil para entender el cómo un árbol de búsqueda se puede utilizar para mostrar el progreso de una búsqueda gráfica. Además, el conocimiento del algoritmo de búsqueda ª Manga es necesario porque la viga de la búsqueda es una modificación de este algoritmo.
Haz algoritmo de búsqueda
Aunque la prioridad a la amplitud de la búsqueda algoritmo está garantizado para encontrar el camino más corto desde un nodo inicial a un nodo objetivo en un gráfico sin ponderar, es imposible utilizar este algoritmo de búsqueda en espacios grandes debido a que su consumo de memoria es exponencial. Esto hace que el algoritmo se quede sin memoria principal antes de una solución se puede encontrar a la mayoría de grandes, los problemas no triviales. Por esta razón, haz la búsqueda se desarrolló en un intento de lograr la mejor solución encontrada por el algoritmo de búsqueda primero en amplitud de memoria sin consumir demasiado.
Para lograr este objetivo, haz la búsqueda utiliza una función heurística, h , para estimar el costo para alcanzar la meta de un nodo dado. También utiliza un ancho de haz, B , que especifica el número de nodos que se almacenan en cada nivel de la-Primera búsqueda en amplitud. Así, mientras que el-primer Buscar tiendas amplitud todos los nodos frontera (los nodos conectados a los vértices de clausura) en la memoria, la viga de algoritmos de búsqueda sólo se almacena la B los nodos con los mejores valores heurística en cada nivel de la búsqueda. La idea es que la función heurística permitirá que el algoritmo para seleccionar los nodos que lo llevará hasta el nodo objetivo, y la anchura del haz hará que el algoritmo para almacenar sólo estos nodos importantes en la memoria y evitar quedarse sin memoria antes de encontrar el estado de la meta .
En lugar de la lista abierta utilizada por el algoritmo de búsqueda-Primera Manga, el Rayo de algoritmos de búsqueda utiliza el HAZ para almacenar los nodos que se ampliarán en el siguiente bucle del algoritmo. Una tabla hash se utiliza para almacenar los nodos que se han visitado, al igual que la lista cerrada -utilizado en la Primera búsqueda en amplitud. Haz la búsqueda inicialmente añade el nodo de inicio al HAZ y la tabla hash . Entonces, cada vez que a través del bucle principal del algoritmo, haz la búsqueda agrega todos los nodos conectados a los nodos en el HAZ a su JUEGO de nodos sucesores y, a continuación añade el B los nodos con los mejores valores de la heurística JUEGO al HAZ y la tabla hash . Tenga en cuenta que un nodo que ya está en la tabla hash no se agrega a la VIGA por un camino más corto a ese nodo ya ha sido encontrado. Este proceso continúa hasta que el nodo meta se encuentra, la tabla hash se llena (lo que indica que la memoria disponible se ha agotado), o el HAZ está vacía después de que el bucle principal ha terminado (lo que indica un callejón sin salida en la búsqueda).
El haz de la búsqueda del algoritmo se muestra por el pseudocódigo a continuación. Este pseudocódigo se supone que la búsqueda de la viga se utiliza en un grafo no ponderado para la variable g se utiliza para no perder de vista la profundidad de la búsqueda, que es el costo de llegar a un nodo en ese nivel.
Pseudocódigo para el algoritmo de búsqueda de haz
/ * Inicialización * / g = 0; tabla_hash = {Inicio}; HAZ = {Inicio} / * * bucle principal / while (HAZ ≠ ∅) {/ / bucle hasta que el rayo no contiene nodos JUEGO = ∅; / / la conjunto vacío / * * JUEGO generar los nodos / for (cada estado en el HAZ) {for (cada sucesor de estado) {if (sucesor == meta) g regreso + 1; JUEGO DE CONJUNTO = ∪ {sucesor}; / / añadir sucesor a SET}} HAZ = ∅; / / el conjunto vacío g = g + 1; / * llenar el HAZ para el siguiente bucle * / while ((SET ≠ ∅) Y (B> | HAZ |)) {/ / establecer no está vacío y el número de nodos en el haz es menor que el sucesor de B = estado en conjunto con menor valor h; JUEGO DE CONJUNTO = \ {estado}; / / eliminar el estado de SET si (estado ∉ tabla_hash) {/ / Estado no es en el caso de tabla_hash (tabla_hash está llena) ∞ retorno; tabla_hash = ∪ tabla_hash {estado} / / añadir un estado a tabla_hash HAZ HAZ ∪ = {estado} / / añadir un estado a HAZ}}} / / meta no se ha encontrado, y HAZ está vacío - Haz la búsqueda no pudo encontrar la vuelta ∞ objetivo;
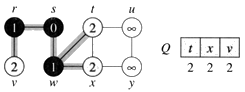
Ejemplo de seguimiento del algoritmo de búsqueda de haz
Las huellas de los siguientes algoritmos de búsqueda utilizan haz dos filas para representar cada bucle principal del algoritmo de la ejecución. La primera fila de cada bucle numerada muestra los nodos agregados a la AJUSTE . Estos nodos están ordenados por su valor heurístico, con el orden alfabético para ordenar los nodos con idéntica h valores. Desde el JUEGO es un conjunto matemático, si un nodo se inserta en el JUEGO más de una vez de los padres múltiples, que sólo aparece en el JUEGO vez. La segunda fila de cada bucle de listas numeradas de los ganglios del JUEGO que se agregan a la VIGA en la segunda parte del bucle principal. Ambas filas también mostrar la tabla hash para mostrar su estado actual. Observe que la tabla hash tiene sólo siete ranuras, lo que indica que el tamaño de la memoria de este ejemplo de seguimiento es de siete. Un sencillo esquema de hashing lineal con los valores fundamentales determinadas por los nombres de nodo 'mod valores ASCII 7 se utiliza para la simplicidad. En los tres de estas listas, los nodos se muestran en el formato nombre_nodo (predecessor_name) . El algoritmo se traza cuatro veces con diferentes valores de B para demostrar las fortalezas y debilidades del algoritmo. Cada traza incluye un árbol de búsqueda que muestra la VIGA en cada nivel de la búsqueda. En la gráfica, los números en los nombres de nodo son los h los valores de los nodos. Estos restos muestran cómo la viga de la búsqueda intenta encontrar el camino más corto desde el nodo que el nodo B en el gráfico se muestra en la Figura 1. (Figura 1 se incluye por encima de cada traza para mayor comodidad.)

Figura 1
Trace 1, B = 1
lazo
número JUEGO (primera fila por lazo paginación)
HAZ (segunda fila por lazo paginación) tabla_hash
HAZ = {I (null)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 JUEGO = {G (I), J (I), E (I), H (I)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 HAZ = {G (I)} tabla_hash = {_, I (nulo), _ _ _ _, G (I)}
2 JUEGO = {D (G), J (G), I (G)} tabla_hash = {_, I (nulo), _ _ _ _, G (I)}
2 HAZ = {D (G)} tabla_hash = {_, I (nulo), _, D (G), _, _, G (I)}
3 JUEGO = {G (D)} tabla_hash = {_, I (nulo), _, D (G), _, _, G (I)}
3 HAZ = {} tabla_hash = {_, I (nulo), _, D (G), _, _, G (I)}
En este punto, el HAZ está vacío, y el Rayo de algoritmos de búsqueda ha llegado a un callejón sin salida en su búsqueda. Desde el nodo G en el JUEGO ya estaba en la tabla hash , no podía ser añadido al HAZ , que dejó el HAZ vacío. Este seguimiento se muestra la mayor debilidad del algoritmo de búsqueda Manga: Una función heurística incorrecta puede llevar el algoritmo en una situación en la que no puede encontrar un objetivo, aunque el camino hacia la meta existe. Al tiempo que aumenta el valor de B puede permitir que la viga de la búsqueda para encontrar el objetivo, el aumento de B por un exceso puede provocar que el algoritmo se quede sin memoria antes de que se encuentra la meta. Por esta razón, la elección de B tiene un gran impacto en la búsqueda de rendimiento de la viga. La figura 2 muestra el HAZ nodos en cada nivel en esta gama de búsqueda muertos.
Figura 1
Trace 2, B = 2
lazo
número JUEGO (primera fila por lazo paginación)
HAZ (segunda fila por lazo paginación) tabla_hash
HAZ = {I (null)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 JUEGO = {G (I), J (I), E (I), H (I)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 HAZ = {G (I), J (I)} tabla_hash = {_, I (nulo), J (I), _, _, _, G (I)}
2 JUEGO = {A (J), D (G), G (J), J (G), E (J), I (G)} tabla_hash = {_, I (nulo), J (I), _, _, _, G (I)}
2 HAZ = {A (J), D (G)} tabla_hash = {A (J), I (nulo), J (I), D (G), _, _, G (I)}
3 JUEGO C = {(A), G (D), J (A)} tabla_hash = {A (J), I (nulo), J (I), D (G), _, _, G (I)}
3 HAZ = {C (A)} tabla_hash = {A (J), I (nulo), J (I), D (G), C (A), _, G (I)}
4 JUEGO B = {(C) [meta que se encuentran - devuelve el algoritmo], A (C)} tabla_hash = {A (J), I (nulo), J (I), D (G), C (A), _, G (I)}
Figura 3
za, el Rayo de la búsqueda algoritmo con éxito el objetivo que se encuentran a través de la ruta de acceso IJACB . Aunque se encontró una solución, esta solución no es óptima debido a IECB es una ruta más corta al nodo objetivo. Una vez más, una función heurística inexacta reduce la eficacia de los algoritmos de búsqueda de haz. La Figura 3 muestra el HAZ nodos en cada nivel de la búsqueda. Tenga en cuenta que sólo un nodo aparece en el HAZ en el nivel tres en el árbol. Esto demuestra que la viga de la búsqueda siempre puede no ser capaz de llenar el HAZ en cada nivel en la búsqueda. En el último nivel del árbol, el nodo A se añaden por primera vez a la CONJUNTO , a continuación, el nodo B (el nodo meta) que se encontró y provocó la búsqueda para completar.
En esta tra
Figura 1
Trace 3, B = 3
lazo
número JUEGO (primera fila por lazo paginación)
HAZ (segunda fila por lazo paginación) tabla_hash
HAZ = {I (null)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 JUEGO = {G (I), J (I), E (I), H (I)} tabla_hash = {_, I (nulo), _ _ _ _ _}
1 HAZ = {G (I), J (I), E (I)} tabla_hash = {_, I (nulo), J (I), _, E (I), _, G (I)}
2 JUEGO = {A (J), C (E), D (G), H (E), G (J), J (E), E (J), H (E), I (E)} tabla_hash = {_, I (nulo), J (I), _, E (I), _, G (I)}
2 HAZ = {A (J), C (E), D (G)} tabla_hash = {A (J), I (nulo), J (I), C (E), E (I), D (G), G (I)}
3 JUEGO B = {(C) [meta que se encuentran - devuelve el algoritmo], A (C), C (A), J (A)} tabla_hash = {A (J), I (nulo), J (I), C (E), E (I), D (G), G (I)}
Figura 4
Con B = 3, el algoritmo de búsqueda haz encontrado el camino óptimo para la meta. Sin embargo, el ancho del haz mayor causado el algoritmo para llenar toda la memoria disponible para la tabla hash. Figura 4 muestra el HAZ nodos en cada nivel en la búsqueda. En el último nivel del árbol, los nodos A , C y J fueron agregados a la JUEGO , y luego el nodo objetivo B se encontró, lo que provocó la búsqueda para completar.
Eficiencia / Análisis de Algoritmos
Por lo general, eficaces para analizar los algoritmos de búsqueda en grafos, considerando cuatro características:
• Integridad: Un algoritmo de búsqueda es completa si se encuentra una solución (nodo meta) cuando existe una solución.
• Optimalidad: Un algoritmo de búsqueda es óptimo si encuentra la solución óptima. En el caso del algoritmo de la viga de la búsqueda, esto significa que el algoritmo debe encontrar el camino más corto desde el nodo inicial al nodo meta.
• complejidad Tiempo: Esta es una orden de estimación de magnitud de la velocidad del algoritmo. La complejidad de tiempo se determina analizando el número de nodos que se generan durante la ejecución del algoritmo.
• complejidad espacial: Esta es una orden de estimación de magnitud del consumo de memoria del algoritmo. La complejidad del espacio está determinada por el número máximo de nodos que se deben almacenar en cualquier momento durante la ejecución del algoritmo.
Integridad
En general, la viga de algoritmos de búsqueda no es completa. Esto se ilustra en seguimiento 1. A pesar de que la memoria no se agota, el algoritmo no logró encontrar el objetivo, ya que no podía añadir nodos al HAZ . Por lo tanto, incluso con tiempo ilimitado y la memoria, es posible que el haz de búsqueda algoritmo perder el nodo objetivo cuando no hay un camino desde el nodo inicial al nodo meta. Una función heurística más precisa y un ancho de haz más grandes pueden mejorar la viga de la búsqueda de posibilidades de encontrar el objetivo. Sin embargo, esta falta de integridad es una de las debilidades principales de los algoritmos de búsqueda de haz.
Optimalidad
Así como el haz de búsqueda algoritmo no es completa, tampoco es garantía de ser óptima. Esto se muestra por Trace 2. En este ejemplo, haz búsqueda encontró el nodo meta, pero no logró encontrar el camino óptimo para la meta, a pesar de que la heurística en la figura 1 es admisible (subestima el costo de la meta de cada nodo) y consistente (subestima el costo entre los nodos vecinos ). Esto sucedió porque el ancho de la viga y una función heurística inexacta causado el algoritmo de perder la ampliación del camino más corto. Una función heurística más precisa y un ancho de haz más grande se puede hacer haz Buscar más probabilidades de encontrar la ruta óptima a la meta.
Tiempo Complejidad
El tiempo para el Rayo algoritmos de búsqueda para completar tiende a depender de la precisión de la función heurística. Una función heurística inexacta por lo general obliga al algoritmo para ampliar más nodos para encontrar la meta e incluso puede hacer que no logran encontrar el objetivo. En el peor de los casos, la función heurística conduce haz Buscar en todo el camino hasta el nivel más profundo en el árbol de búsqueda. Por lo tanto, el caso peor momento es O (Bm) , donde B es el ancho del haz y m es la profundidad máxima de cualquier ruta en el árbol de búsqueda. Esta complejidad de tiempo es lineal porque el haz algoritmos de búsqueda sólo se expande B nodos en cada nivel, no se ramifican más ampliamente en cada nivel, como los algoritmos de búsqueda que tienen muchas complejidades tiempo exponencial. La velocidad con la que este algoritmo se ejecuta es una de sus mayores fortalezas.
Espacio Complejidad
Búsqueda de consumo de memoria del haz es su rasgo más deseable. Debido a que el algoritmo sólo almacena B nodos en cada nivel en el árbol de búsqueda, el caso del espacio de complejidad-peor es O (Bm) , donde B es el ancho del haz y m es la profundidad máxima de cualquier ruta en el árbol de búsqueda. Este consumo de memoria lineal permite la viga de la búsqueda para investigar muy profundamente en los espacios de búsqueda grandes y, potencialmente, encontrar soluciones que otros algoritmos no pueden llegar.
Comparar con su libro de texto
Algoritmos puede mirar de manera diferente, pero siguen operando en casi la misma manera. Comparar el pseudocódigo anterior con la descripción de tu libro de texto (si está disponible).
A continuación, considere estas preguntas:
1. ¿Tiene su libro de texto de usar una tabla hash para almacenar los nodos que se han ampliado? Si no, ¿cómo almacenar estos nodos?
2. ¿Tiene su libro de texto de explicar qué tipo de estructura se debe utilizar para implementar el JUEGO ? Si es así, ¿qué estructura que se utiliza?
Explorando el comportamiento dinámico del algoritmo
Explora el algoritmo en JHAVÉ
Se puede practicar la viga algoritmos de búsqueda usando el sistema de visualización JHAVÉ algoritmo. Si usted no ha utilizado JHAVÉ antes, por favor, tómese el tiempo para ver las instrucciones en JHAVÉ utilizando en primer lugar. Si su navegador compatible con Java Webstart, puede iniciar una visualización de los algoritmos de búsqueda de haz directamente desde este enlace .
La búsqueda de la visualización del haz tiene quince ejemplo gráficos con los que usted puede experimentar. Los cuatro primeros ejemplos, perfect1 , perfect2 , perfect3 y perfect4 , tienen perfecta funciones heurísticas que permiten que el algoritmo para encontrar la ruta óptima si se dispone de memoria suficiente. Los siguientes siete gráficos, errant1 , errant2 , errant3 , errant4 , errant5 , errant6 y errant7 , han inexacta funciones heurístico que puede conducir el algoritmo para encontrar caminos que son más largos que el óptimo si la anchura del haz es demasiado pequeño. Los últimos cuatro gráficos, END1 , end2 , end3 y end4 , como resultado de fin de búsquedas muertos cuando se utiliza más pequeños anchos de haz. Para cada uno de estos ejemplos, puede establecer los valores de la anchura del haz, B , y el tamaño de la memoria, M , para ver cómo diferentes valores de estos parámetros afectan el resultado del algoritmo en el gráfico. Por último, el nivel de detalle opción le permite controlar cómo los pasos de animación a través de la pseudocódigo. La opción de alto detalle muestra cómo cada nodo se agrega a la AJUSTE uno por uno y es útil cuando se están menos familiarizados con el algoritmo. La opción de detalle bajo genera todos los nodos en el JUEGO en un solo paso, para que pueda centrarse más fácilmente en los demás aspectos del algoritmo.
Paso a través de los ejemplos de la visualización y la prueba de cómo los diferentes parámetros modificar los resultados obtenidos por el algoritmo de la viga de la búsqueda. Responda a las preguntas que aparecen durante la visualización para evaluar su comprensión del algoritmo. Cuando constantemente puede responder a las preguntas correctamente, pruebe los ejercicios siguientes.